



永华证券配资平台 一文看懂金融行业AI大模型智算网络架构

生成式人工智能是当前最具影响力的创新科技,越来越多的银行、保险和证券机构已经开启了生成式人工智能的探索和实践,AI大模型逐渐渗透到金融行业的各个角落,正在成为金融行业创新的重要驱动力。
1 金融行业千卡和千亿参数级别大模型已应用部署
金融头部客户已经部署千卡和千亿参数级别大模型,这些模型在提高效率、降低风险、改善客户体验等多个应用场景展现出巨大潜力,被认为是银行业的“新质生产力”。从2023年金融行业的年度报告和相关资讯中,我们可以看到AI大模型在金融领域的应用和发展取得了显著进展,例如,中国工商银行建立了全栈自主可控的千亿级AI大模型技术体系,应用在对公信贷、远程银行、智能客服和智慧办公等场景;中国太保打造了首个保险行业千亿级大模型,覆盖集团审计、产险、寿险、健康险等多个核心业务板块,建设了审计、财险在线理赔和健康险理赔等AI助手,利用大模型实现了流程高度自动化,健康险系统的核赔准确率高达89%;国泰君安联合财跃星辰推出业内首家千亿参数多模态证券垂类大模型——君弘灵犀大模型,为客户在智能投顾问答、投研内容生产和交互模式上带来全新的体验。
2 金融行业AI大模型需要什么样的智算网络架构
随着大模型的训练参数不断增长,AI大模型的训练参数将从千亿迈向万亿级别。对于千亿和万亿参数级别场景来说,每块GPU都有显存容量限制,AI训练任务已经无法仅靠单台服务器来完成,需要将模型参数分拆到多块GPU上来存储,计算集群采用分布并行训练策略协作完成。AI大模型常用的分布式训练策略包括流水并行、数据并行和模型并行,其中模型并行在单台主机多卡内部交换通信,流水并行和数据并行需要跨主机借助高速网络交互通信。大模型训练特点是计算和通信周期性重复迭代,训练时间包括计算时间和通信时间,减少模型训练的通信时间对于保障大模型高效训练至关重要。如图1所示,通信时间可分解为服务器内存拷贝与协议栈处理时延、数据传输时间和交换机转发时延。

图1 模型训练通信时间分解
为了降低服务器内转发时延,网络协议从传统TCP转向RoCE(RDMA over Converged Ethernet),转发时延从毫秒级降低到微秒级。数据传输时间=通信传输的数据量/有效带宽, 网络有效带宽越大,意味着在单位时间内可传输更多的数据,有助于缩短数据传输时间,从而显著提升模型的训练效率。大模型训练过程中跨服务器传输的数据量大于1GB,当使用400GE交换机端口进行线速转发时,数据传输时间为几十毫秒级,如下表1所示,数据传输时间占比超过99%,对通信时间影响最大,交换机时延占比可忽略不计。
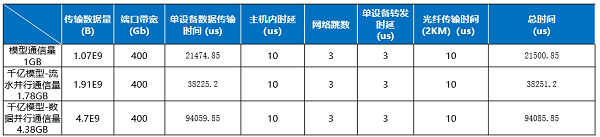
表1 大模型训练场景,交换机转发时延占比分析
AI训练网络中的一个网元节点故障会影响数十个以上计算节点的连通性,网络故障会影响大模型的训练效率,甚至导致模型训练失败。网络可靠性决定了集群算力稳定性,网络吞吐性能决定了集群算力效率,因此,高可靠、高吞吐和易运维的网络可显著降低模型训练成本,对AI大模型的构建尤为重要。
2.1 如何构建高可靠的智算网络架构
AI训练网络架构可划分成三层组网和二层组网,三层和二层组网架构对比如下图2,设备上下行带宽都采用1:1无收敛,三层组网在二层组网基础上需要增加光模块来实现不同层级之间的互连,互连的光模块数量翻倍,这意味着光模块的故障率相对上升了一倍,网络的可靠性相对较差,建设成本也较高。随着芯片转发能力不断提升,二层组网架构能够支持万卡集群建设规模,满足千亿和万亿参数级别大模型训练需求。

图2 大模型参数面三层和二层组网架构对比
2.1.1 高可靠和易运维的框盒/框框二层组网
金融行业AI集群训练优先采用二层组网架构,网络架构以框盒或框框架构为主。框式设备基于信元CLOS无阻塞架构,具备主控冗余、网板冗余、转发面和控制分离等特点,这些设计使得网络系统具有更高的可靠性和稳定性,能够确保持续、稳定地运行,可靠性和扩展性高于盒式设备,另外,框框组网可大幅减少RoCE网络中的网元数量,建设和维护相对简单。例如,针对400GE端口6000卡集群规模,框盒和框框组网对比,如下图3,盒式设备端口密度为32个400GE,框式采用8槽位设备,线卡端口密度为40个400GE,框框组网需要58台设备,框盒需要396台设备,框框相比框盒组网的网元数量减少了85%。当然,框框组网也有不足之处,框式设备相对盒式设备在转发时延和功耗上大一些,但如前文分析,大模型场景交换机转发时延可忽略,因此,框框组网需要重点考虑机房供电情况,新建机房可满足8槽位和4槽位交换机功耗,老旧机房可能会面临供电改造问题。
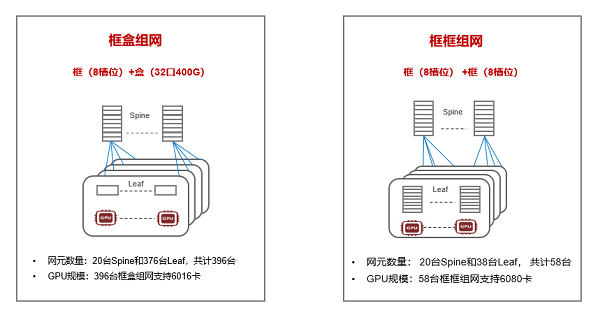
图3 400GE端口6000千卡三层和二层组网对比
2.1.2 光模块通道抗损和脏污智能识别技术提升网络接入可靠性
随着大量(百万级)200GE/400GE光模块在网络中长期运行,积累了大量故障数据,统计分析显示,400G/200G光模块每年因为通道故障造成的失效率高达6.3‰,万卡集群每年因光模块失效引发的训练中断可达到96次,其中70%为单通道故障,30%为脏污松动引起,严重影响AI训练效率。在大模型集群200GE和400GE端口接入场景,200GE和400GE多模光模块内部包含多个激光器发射通道,这些通道并行工作以支持高速传输速率,通过隔离光模块单通道故障,可实现光模块降速但不中断转发,如下图4所示。另外,利用AI算法在训前识别光模块脏污与松动,可以提前预防和解决潜在的故障问题。通过光模块通道抗损和脏污智能识别技术方案,光模块年失效率可降低至0.4‰,网络可靠性提升15倍,不仅提升了AI训练效率,还能节约相应训练成本。
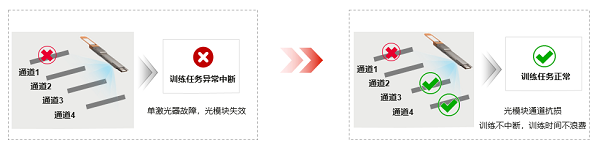
图4 通道抗损技术实现模块故障不中断转发
2.2 如何构建高吞吐的智算网络架构
智算网络采用标准的Spine-Leaf架构,在选路方面采用ECMP哈希算法,但AI训练的流量特征是“流量条数少”和“每条流量大”,传统ECMP哈希会造成链路上流量不均,网络有效吞吐在30%~60%左右,降低了AI训练效率。基于流的网络级负载均衡算法是当前成熟且广泛应用部署的方案,用于解决网络中的流量不均衡问题。这种算法主要依赖于全局流量矩阵来进行流量的分配和调度,可以实现全网流量的确定性转发,从而达到网络吞吐最优,有效解决了ECMP哈希不均的问题。如下图5所示,AI集群采用8卡16节点训练场景,测试AllReduce集合通信性能,网络有效带宽最大提升了53%,可以显著减少模型训练中参数交互的通信时间,极大地提升了AI训练效率。

图5 网络级负载均衡算法,网络有效带宽最大提升53%
2.3 如何构建易运维的智算网络架构
2.3.1 算网协同方案提升智算网络部署效率
智算网络采用高性能RoCE协议,需要计算侧与网络侧紧密协同,以确保RoCE相关参数配置的一致性,如果计算和网络依赖人工解耦配置,容易出现配置不一致和效率低下的问题。另外,AI集群组网中存在大量的链路互联,这使得连线配置和错误排除变得更加困难。基于AI大模型的网络建设实践,计算侧和网络侧协同方案已取得了显著进展,算网协同方案可基于大模型详细设计文档自动生成网络配置,并实现自动加载,这意味着计算和网络可以即插即用,同时还具备了自动校验和排查链路互联错误的功能,从而提升了网络部署的效率和准确性,智算网络部署时间从月级缩减到天级,针对千卡和万卡级别大模型,一周内实现算网方案部署,部署效率提升了4倍。
2.3.2 训练任务网络路径可测量,分钟级故障定位与恢复
AI大模型训练周期长,训练过程会存在故障中断的风险,需要快速诊断故障并进行恢复,算力网络可视化运维变得尤为重要。通过采集设备配置信息,还原GPU卡间流量转发路径,实现算力卡和流量路径可观测和可度量,运维人员能够直观地了解流量路径的实时状态,便于监控和管理。如下图6所示,借助可视化运维软件,能够分钟级快速问题定界和故障恢复,运维工作变得更加高效和智能化。
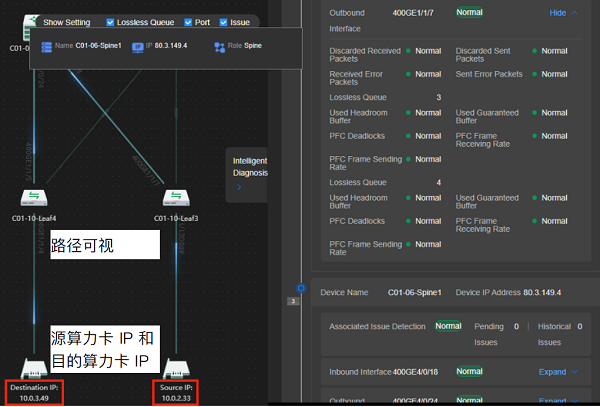
图6 算力卡间通信转发路径可视化
3 展望
AI大模型在金融领域的应用正在不断深化,推动金融行业从数字化阶段迈进数智化阶段,AI大模型建设将为金融行业带来深刻的变革和前所未有的机遇。未来随着大模型GPU算力持续提升,网络架构作为大规模训练集群的重要基石,也需要不断迭代升级以支持更高效的数据传输和处理,提供400GE/800GE超宽和超智能网络方案永华证券配资平台,通过引入智能化运维技术,如故障预测和自愈等算法技术,为AI大模型训练构筑高可靠和高吞吐的网络底座,为AI技术的持续发展和广泛应用奠定了坚实基础。



